概览
这篇文章出现的时间比计划迟了一些,一方面是因为近期一直忙着总结去年学过的东西,另一方面也是因为个人觉得整个分布式系统的理论太过庞大,一直苦于难以找到合适的切入点下手。
本文就将围绕着什么是分布式系统,为什么需要分布式系统以及分布式系统的核心理论(CAP 理论)进行阐述,在介绍理论的同时我也会穿插讲解存储系统(Redis 和 Mysql)是如何践行 CAP 理论的。
什么是分布式系统
A distributed system, also known as distributed computing, is a system with multiple components located on different machines that communicate and coordinate actions in order to appear as a single coherent system to the end-user.
分布式系统是一组通过网络传递消息并协调他们行为来对外提供一致服务的计算机节点。因为他们之间彼此独立,所以具有以下特性:
- 组件的并发性
- 故障的独立性
- 缺少全局时钟
前两点特性不难理解,第三点提到的缺少全局时钟是什么意思呢?无论是计算机领域还是现实生活中,时钟的意义都包括确定事情的发生顺序,两个同样的操作可能因为顺序不同产生不同的结果(比如存款与取款)。在分布式系统中,虽然节点之间可以同步时间,但是因为网络时延等因素,总会存在误差的可能。
为什么需要分布式系统
在谈论为什么需要分布式系统时,我们需要了解分布式系统的出现为我们解决了什么问题?在面对庞大的计算任务和并发请求时,往往我们通过扩展的方式来提高服务的整体性能。其中,扩展的方式包括:
- 横向扩展(Scale Out)
- 纵向扩展(Scale Up)
所谓纵向扩展即通过提高运行节点的硬件规格来提高服务性能。在大多数情况,这都是最简单有效的方法。但是,随着单机节点的配置不断升高,受硬件水平发展的限制(摩尔定律), 纵向扩展的边际成本也不断增大。同时,很多服务也不能完全受益于纵向扩展。比如过大的内存可能会导致 Redis 在通过 fork() 生成子进程时阻塞太久。受限于纵向扩展的瓶颈与成本,横向扩展在某些场景下成为更适合的选择。横向扩展通过增加运行的节点个数来提高服务整体的性能。理论上服务的整体性能与运行的节点个数是成线性关系的,但是受限于节点间通信的时延以及部分无法并行执行的任务,真实的性能水平更符合于下图中的 USL 扩展曲线。
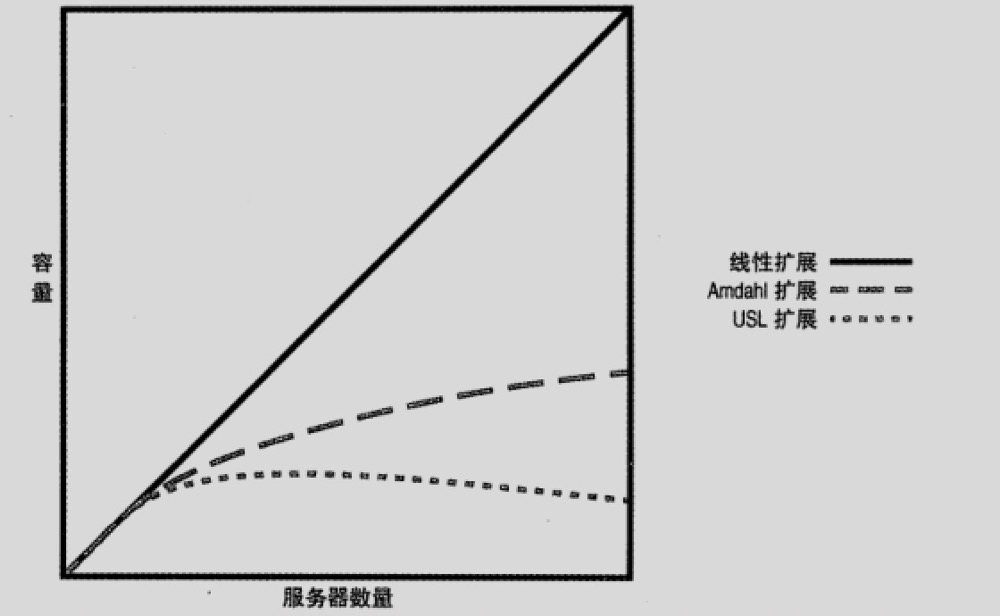
虽然如此,横向扩展相较于纵向扩展往往只需要低的成本,并且能够避免单点故障,但是这同样也引来了更大的系统复杂度,因为节点之间不共享内存,只能通过 HTTP,RPC,消息队列等形式共享信息,如何保证临界资源不被同时获取以及部分任务并发执行结果的正确性成为程序设计的首要问题。通过横向扩展的方式运行的这一组节点我们就可以看作一个分布式系统。
分布式算法的演进
在前面我们有提到,通过横向扩展的方式构建分布式系统虽然能够提高整体服务性能,但同时也带来了系统设计的复杂性。 Peter Deutsch 在90年代发表了 Fallacies of distributed computing, 其中包括8个关于分布式系统的错误假设:
- 网络是可靠的
- 网络没有延迟
- 带宽是无限的
- 网络是安全的
- 网络拓扑不会改变
- 网络上有管理员
- 网络传输没有成本
- 网络是同质的

图2.Fallacies of distributed computing(摘自 https://www.infoq.com/presentations/distributed-systems-complexity-human-factor/)
正因为上述问题的存在,如何保证分布式节点之间的一致性,整体服务的可用性等成为分布式算法研究的重要领域。
CAP 理论
CAP 理论起源于埃里克·布鲁尔 2000 年提出的一个猜想。该理论指出任何一个分布式系统不可能同时满足以下三点:
- 一致性(Consistency),即客户端访问的所有节点得到的是相同的副本
- 可用性(Availability),每次请求都能获取到非错的响应,但是不保证获取的数据为最新数据
- 分区容错性(Partition tolerance), 以实际效果而言,分区相当于对通信的时限要求
其中一致性和可用性都不难理解,而分区容错性的分区一般可以类比为可用区。当我们为了提高服务或者资源的稳定性,或者实现跨地理位置的低延迟访问,我们可能会将服务部署到多个可用区进行冗余。而一旦可用区间通信中断或者阻塞,那么此时就产生分区。
因为不能同时满足 CAP 三者,我们在设计系统时往往要从 CA,AP 和 CP 之间进行选择。
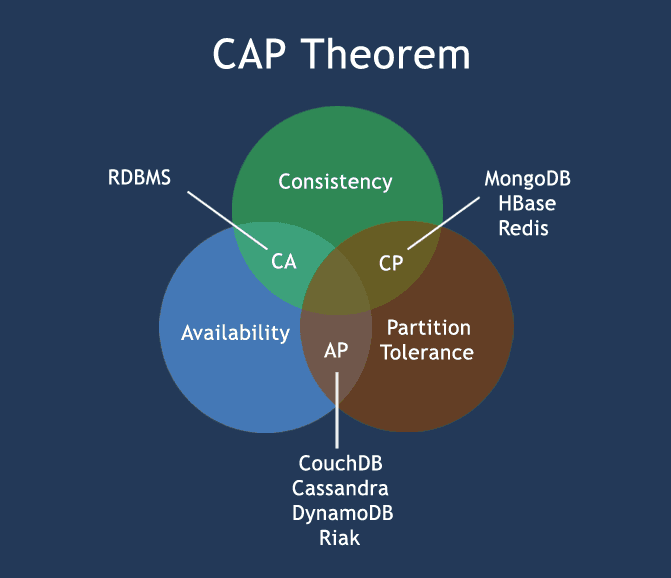
选择 CA,意味着放弃了分区容错性,也就是单机模式,相当于不考虑分布式架构,比如单机模式的 RDBMS.
选择 AP,意味着当分区发生时,允许分区两侧正常提供服务,通过柔性事务达到最终一致性。实现柔性事务的方式包括 TCC(Try - Confirm - Cancel),异步确保等。
选择 CP,意味着牺牲可用性来保证强一致性。当分区发生时,此时服务完全不可用或部分分区的服务不可用。一般通过 Raft,Paxos 等协议来保证强一致性。
我们以 Redis 脑裂的过程来更好地理解 AP 与 CP 之间的区别与联系。在 Redis 哨兵模式下,由哨兵选举出来的 master 节点负责读写请求,而 slave 只能接收读请求。当 master 突然和哨兵以及 slave 节点位于不同的分区时,此时哨兵因为无法连接 master 节点而开始新一轮的 leader 选举,被选中的新 master 节点和另一分区的 master 节点都可以进行写入操作,即 AP 模式。当网络恢复,哨兵将旧 master 节点降级为 slave 时,分区期间对旧 master 节点的写入数据将丢失。
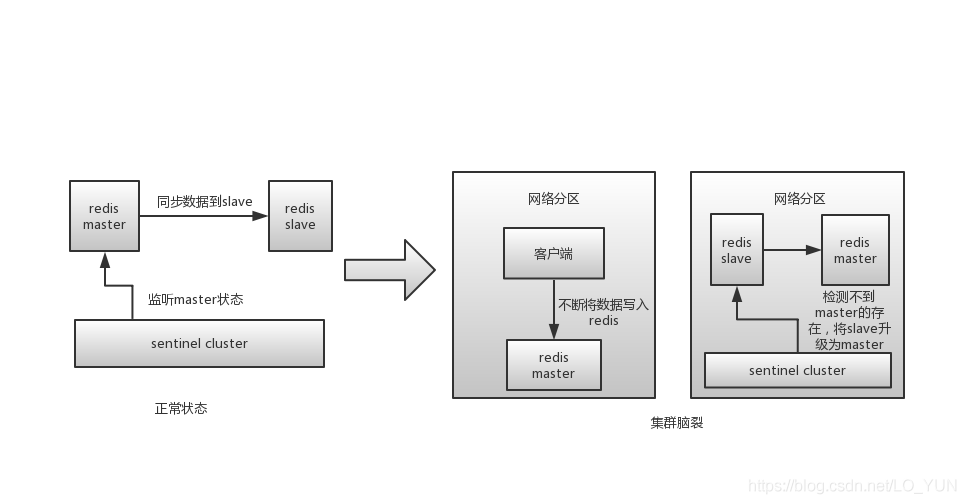
当我们通过设置 min-replicas-to-write 和 min-replicas-max-lag 来限制分区发生时的孤立 master 节点时,则对应于 CP 模式。
总结
本文主要介绍了分布式系统是一组通过网络传递消息并协商行为来对外提供一致服务的计算机节点,其产生原因包括通过横向扩展的方式来提高整体服务的性能。因为节点间通信延时等问题,所以导致在设计系统时需要权衡可用性,一致性以及分区容错性,其中 CAP 理论提出任何一个分布式系统不能同时满足以上三者。
本文参考
https://rickhw.github.io/2018/08/11/Architecture/CAP-Theorem/
https://www.infoq.cn/article/cap-twelve-years-later-how-the-rules-have-changed/
https://en.wikipedia.org/wiki/Distributed_computing
https://rickhw.github.io/2018/06/18/Architecture/Gossip-in-Distributed-Systems/
https://www.infoq.com/presentations/distributed-systems-complexity-human-factor/
https://www.timetoast.com/timelines/2346231
https://en.wikipedia.org/wiki/Fallacies_of_distributed_computing